Our Blueprint for Data That Works: Understanding ETL, ELT & Reverse ETL
Been deep in the weeds building out our "Unified Data Blueprint" series over on SEOSiri, and just published a chapter I think many of you bootstrapping or scaling your projects will find super relevant: Engineering Your Data Flow with ETL, ELT & Reverse ETL.
Sounds a bit jargon-heavy, I know. But stick with me – getting this right can be the difference between data being a headache and data being your superpower.
The Core Problem Many of Us Face:
We're collecting data from everywhere – our app, Stripe, Google Analytics, marketing tools, customer support... but it's often:
Siloed (stuck in different places)
Messy (inconsistent formats)
Hard to use for making decisions or personalizing experiences.
What We Covered (The TL;DR):
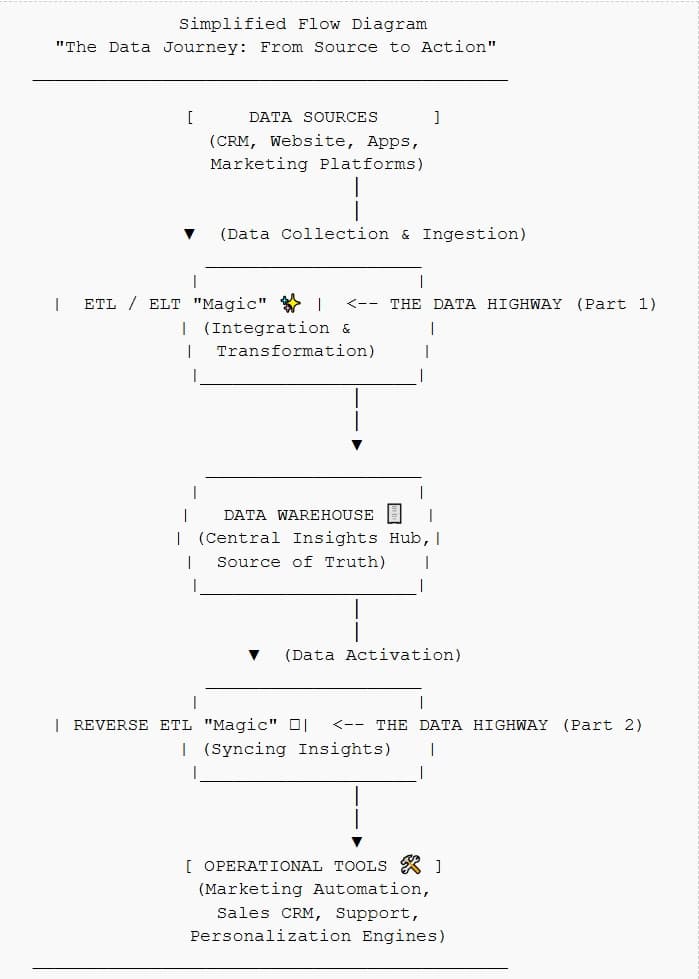
I break down three key approaches to moving and transforming data so it becomes useful:
ETL (Extract, Transform, Load): The classic. Pull data, clean/reshape it before it hits your database/warehouse. Good for structured stuff and when pre-load cleanliness is paramount. Can be slow for big, messy data.
ELT (Extract, Load, Transform): The modern disruptor, especially with cloud warehouses (BigQuery, Snowflake, etc.). Dump raw data in, then use the warehouse's power to transform it. Super flexible, faster ingestion, great for when you want to explore raw data.
Reverse ETL (This is where it gets REALLY interesting for indie hackers!):
This is about taking all those juicy, processed insights from your data warehouse (your "single source of truth") and piping them back into the tools you use every day.
Think: Sending a "High Churn Risk" segment from your warehouse directly to your email marketing tool for a targeted re-engagement campaign.
Or, pushing "Power User" status into your CRM so your sales/support knows who they're talking to.
This CLOSES THE LOOP and makes your data actionable by your operational teams (even if that team is just you!).
Why This Matters for Us Indie Hackers:
Better Decisions: Stop guessing, start using real data.
Automation: Reverse ETL can automate so many personalized touchpoints.
Efficiency: Less manual data wrangling.
Scalability: As you grow, having solid data flows is non-negotiable. You don't want to hit a wall because your "data stack" is a pile of Zapier zaps and manual CSV uploads (been there!).
I've found that truly understanding these concepts helps you choose the right (often lean) tools and build a data foundation that can support growth without breaking the bank or requiring a dedicated data engineering team from day one.
Want a full deep dive?
The chapter goes into more detail on the pros/cons, when to use each, and how they fit into a larger "Unified Data Blueprint." It's all up on the SEOSiri blog – no paywall, just sharing what we're learning.
➡️ Read the full Chapter 6 here: Understanding ETL, ELT & Reverse ETL
Curious to hear from you all:
How are you currently managing your data flows? What tools are you using?
Any big "aha!" moments you've had with ETL, ELT, or especially Reverse ETL?
What are your biggest data headaches as an indie hacker?
Let's chat!